

索引
索引的概念:索引的出现其实就是为了提高数据查询的效率,就像书的目录一样。
在 MySQL 中,索引是在存储引擎层实现的,
索引的常见模型
- 哈希表
- 有序数组
- 搜索树
哈希表
哈希表是一种以键 - 值(key-value)存储数据的结构,把值放在数组里,用一个哈希函数把 key 换算成一个确定的位置,然后把 value 放在数组的这个位置。不可避免地,多个 key 值经过哈希函数的换算,会出现同一个值的情况。处理这种情况的一种方法是,拉出一个链表。
由于哈希表的索引不是递增的,所以新增的时候会很快,但是因为不是有序的,所以哈希索引做区间查询的速度是很慢的。
哈希表这种结构适用于只有等值查询的场景,比如 Memcached 及其他一些 NoSQL 引擎。
有序数组
有序数组索引只适用于静态存储引擎,因为你往中间插入一个记录就必须得挪动后面所有的记录,成本太高
时间复杂度是:O(log(N))
二叉树
特点:节点左子树所有结点的值小于父节点的值,右子树所有结点的值大于父节点的值。
查询时间复杂度O(log(N)),更新时间复杂度O(log(N))

但是实际上大多数的数据库存储却并不使用二叉树。其原因是,索引不止存在内存中,还要写到磁盘上
举栗:
你可以想象一下一棵 100 万节点的平衡二叉树,树高 20。一次查询可能需要访问 20 个数据块。在机械硬盘时代,从磁盘随机读一个数据块需要 10 ms 左右的寻址时间。也就是说,对于一个 100 万行的表,如果使用二叉树来存储,单独访问一个行可能需要 20 个 10 ms 的时间
nnoDB 的索引模型
在 InnoDB 中,表都是根据主键顺序以索引的形式存放的,这种存储方式的表称为索引组织表。
InnoDB 使用了 B+ 树索引模型,所以数据都是存储在 B+ 树中的。
每一个索引在 InnoDB 里面对应一棵 B+ 树。
【主键索引】
主键索引的叶子节点存的是整行数据。在 InnoDB 里,主键索引也被称为聚簇索引(clustered index)
【非主键索引】
非主键索引的叶子节点内容是主键的值。在 InnoDB 里,非主键索引也被称为二级索引(secondary index)。
主键长度越小,普通索引的叶子节点就越小,普通索引占用的空间也就越小。
【两者的区别】
举个栗子:
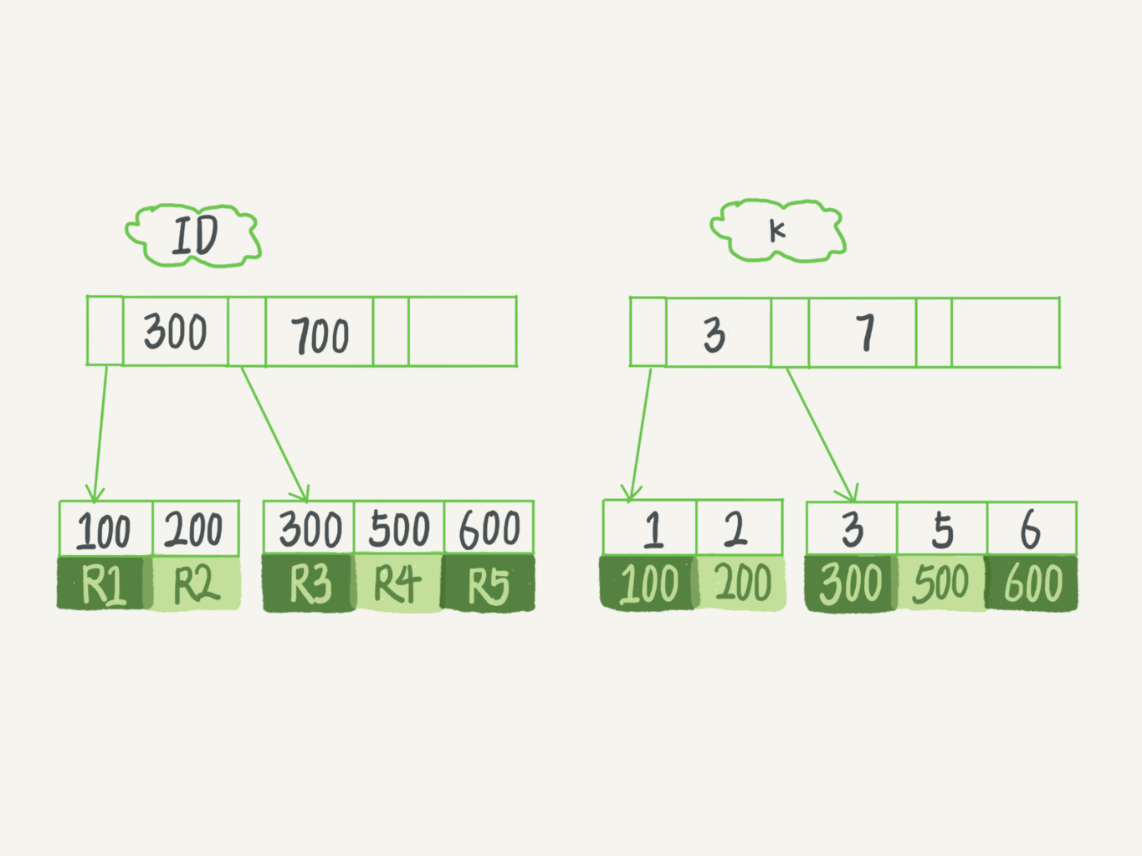
- 如果语句是 select * from T where ID=500,即主键查询方式,则只需要搜索 ID 这棵 B+ 树;
- 如果语句是 select * from T where k=5,即普通索引查询方式,则需要先搜索 k 索引树,得到 ID 的值为 500,再到 ID 索引树搜索一次。这个过程称为回表。
基于非主键索引的查询需要多扫描一棵索引树
B+ 树能够很好地配合磁盘的读写特性,减少单次查询的磁盘访问次数。


评论 (0)