搜索到
60
篇与
的结果
-
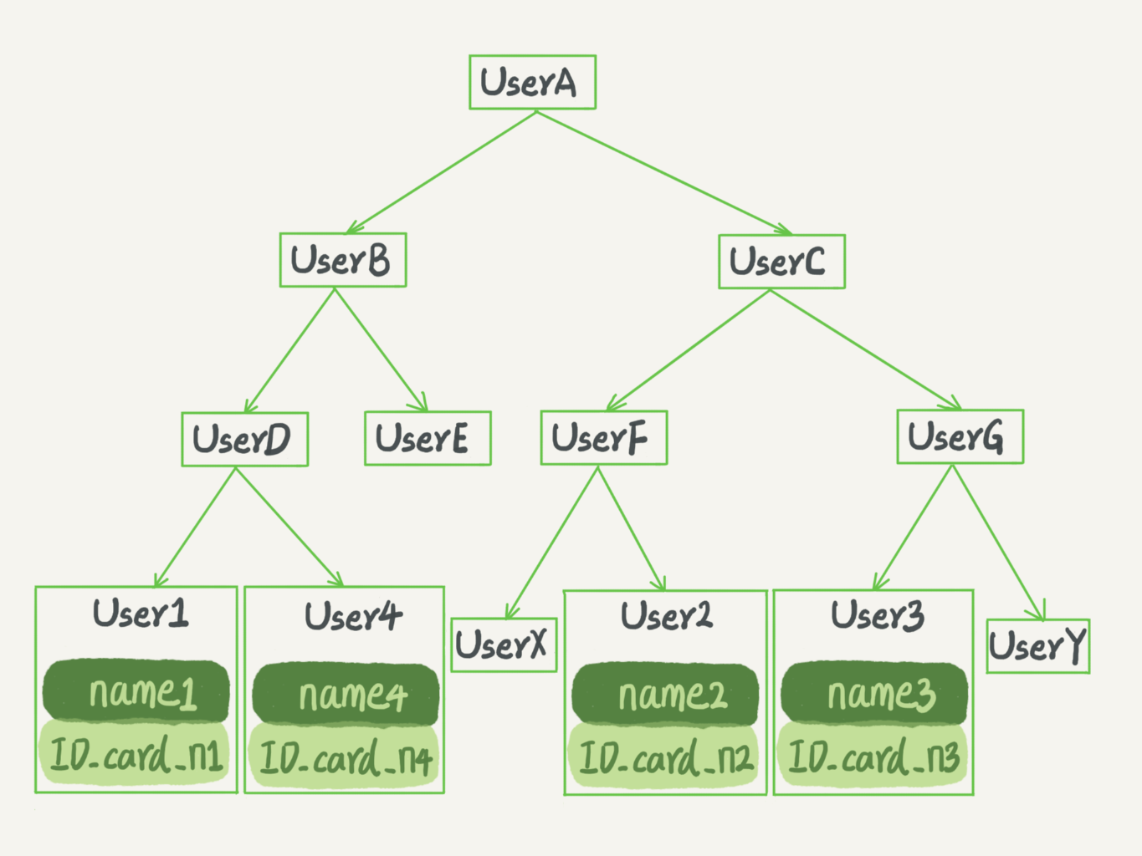
 笔记 | 深入浅出索引(上) 索引索引的概念:索引的出现其实就是为了提高数据查询的效率,就像书的目录一样。在 MySQL 中,索引是在存储引擎层实现的,索引的常见模型哈希表有序数组搜索树哈希表哈希表是一种以键 - 值(key-value)存储数据的结构,把值放在数组里,用一个哈希函数把 key 换算成一个确定的位置,然后把 value 放在数组的这个位置。不可避免地,多个 key 值经过哈希函数的换算,会出现同一个值的情况。处理这种情况的一种方法是,拉出一个链表。由于哈希表的索引不是递增的,所以新增的时候会很快,但是因为不是有序的,所以哈希索引做区间查询的速度是很慢的。哈希表这种结构适用于只有等值查询的场景,比如 Memcached 及其他一些 NoSQL 引擎。有序数组有序数组索引只适用于静态存储引擎,因为你往中间插入一个记录就必须得挪动后面所有的记录,成本太高时间复杂度是:O(log(N))二叉树特点:节点左子树所有结点的值小于父节点的值,右子树所有结点的值大于父节点的值。查询时间复杂度O(log(N)),更新时间复杂度O(log(N))但是实际上大多数的数据库存储却并不使用二叉树。其原因是,索引不止存在内存中,还要写到磁盘上举栗:你可以想象一下一棵 100 万节点的平衡二叉树,树高 20。一次查询可能需要访问 20 个数据块。在机械硬盘时代,从磁盘随机读一个数据块需要 10 ms 左右的寻址时间。也就是说,对于一个 100 万行的表,如果使用二叉树来存储,单独访问一个行可能需要 20 个 10 ms 的时间nnoDB 的索引模型在 InnoDB 中,表都是根据主键顺序以索引的形式存放的,这种存储方式的表称为索引组织表。InnoDB 使用了 B+ 树索引模型,所以数据都是存储在 B+ 树中的。每一个索引在 InnoDB 里面对应一棵 B+ 树。【主键索引】主键索引的叶子节点存的是整行数据。在 InnoDB 里,主键索引也被称为聚簇索引(clustered index)【非主键索引】非主键索引的叶子节点内容是主键的值。在 InnoDB 里,非主键索引也被称为二级索引(secondary index)。主键长度越小,普通索引的叶子节点就越小,普通索引占用的空间也就越小。【两者的区别】举个栗子:如果语句是 select * from T where ID=500,即主键查询方式,则只需要搜索 ID 这棵 B+ 树;如果语句是 select * from T where k=5,即普通索引查询方式,则需要先搜索 k 索引树,得到 ID 的值为 500,再到 ID 索引树搜索一次。这个过程称为回表。基于非主键索引的查询需要多扫描一棵索引树B+ 树能够很好地配合磁盘的读写特性,减少单次查询的磁盘访问次数。
笔记 | 深入浅出索引(上) 索引索引的概念:索引的出现其实就是为了提高数据查询的效率,就像书的目录一样。在 MySQL 中,索引是在存储引擎层实现的,索引的常见模型哈希表有序数组搜索树哈希表哈希表是一种以键 - 值(key-value)存储数据的结构,把值放在数组里,用一个哈希函数把 key 换算成一个确定的位置,然后把 value 放在数组的这个位置。不可避免地,多个 key 值经过哈希函数的换算,会出现同一个值的情况。处理这种情况的一种方法是,拉出一个链表。由于哈希表的索引不是递增的,所以新增的时候会很快,但是因为不是有序的,所以哈希索引做区间查询的速度是很慢的。哈希表这种结构适用于只有等值查询的场景,比如 Memcached 及其他一些 NoSQL 引擎。有序数组有序数组索引只适用于静态存储引擎,因为你往中间插入一个记录就必须得挪动后面所有的记录,成本太高时间复杂度是:O(log(N))二叉树特点:节点左子树所有结点的值小于父节点的值,右子树所有结点的值大于父节点的值。查询时间复杂度O(log(N)),更新时间复杂度O(log(N))但是实际上大多数的数据库存储却并不使用二叉树。其原因是,索引不止存在内存中,还要写到磁盘上举栗:你可以想象一下一棵 100 万节点的平衡二叉树,树高 20。一次查询可能需要访问 20 个数据块。在机械硬盘时代,从磁盘随机读一个数据块需要 10 ms 左右的寻址时间。也就是说,对于一个 100 万行的表,如果使用二叉树来存储,单独访问一个行可能需要 20 个 10 ms 的时间nnoDB 的索引模型在 InnoDB 中,表都是根据主键顺序以索引的形式存放的,这种存储方式的表称为索引组织表。InnoDB 使用了 B+ 树索引模型,所以数据都是存储在 B+ 树中的。每一个索引在 InnoDB 里面对应一棵 B+ 树。【主键索引】主键索引的叶子节点存的是整行数据。在 InnoDB 里,主键索引也被称为聚簇索引(clustered index)【非主键索引】非主键索引的叶子节点内容是主键的值。在 InnoDB 里,非主键索引也被称为二级索引(secondary index)。主键长度越小,普通索引的叶子节点就越小,普通索引占用的空间也就越小。【两者的区别】举个栗子:如果语句是 select * from T where ID=500,即主键查询方式,则只需要搜索 ID 这棵 B+ 树;如果语句是 select * from T where k=5,即普通索引查询方式,则需要先搜索 k 索引树,得到 ID 的值为 500,再到 ID 索引树搜索一次。这个过程称为回表。基于非主键索引的查询需要多扫描一棵索引树B+ 树能够很好地配合磁盘的读写特性,减少单次查询的磁盘访问次数。 -
笔记 | 事务隔离:为什么你改了我还看不见? 【事务】事务支持是在引擎层实现的,不是所有的引擎都支持事务,只有InnoDB支持事务特性:原子性、一致性、隔离性、持久性Atomicity(原子性):一个事务(transaction)中的所有操作,或者全部完成,或者全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。即,事务不可分割、不可约简。 Consistency(一致性):在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设约束、触发器、级联回滚等。 Isolation(隔离性):数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括未提交读(Read uncommitted)、提交读(read committed)、可重复读(repeatable read)和串行化(Serializable)。 Durability(持久性):事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。SQL 标准的事务隔离级别包括:读未提交(read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(serializable )读未提交:一个事务还没提交时,它做的变更就能被别的事务看到读提交: 一个事务提交之后,它做的变更才会被其他事务看到可重复读:一个事务执行过程中看到的数据,总是跟这个事务在启动时看到的数据是一致的。当然在可重复读隔离级别下,未提交变更对其他事务也是不可见的串行化:顾名思义是对于同一行记录,“写”会加“写锁”,“读”会加“读锁”。当出现读写锁冲突的时候,后访问的事务必须等前一个事务执行完成,才能继续执行【举个栗子】mysql> create table T(c int) engine=InnoDB;insert into T(c) values(1);若隔离级别是“读未提交”, 则 V1 的值就是 2。这时候事务 B 虽然还没有提交,但是结果已经被 A 看到了。因此,V2、V3 也都是 2。若隔离级别是“读提交”,则 V1 是 1,V2 的值是 2。事务 B 的更新在提交后才能被 A 看到。所以, V3 的值也是 2。若隔离级别是“可重复读”,则 V1、V2 是 1,V3 是 2。之所以 V2 还是 1,遵循的就是这个要求:事务在执行期间看到的数据前后必须是一致的。若隔离级别是“串行化”,则在事务 B 执行“将 1 改成 2”的时候,会被锁住。直到事务 A 提交后,事务 B 才可以继续执行。所以从 A 的角度看, V1、V2 值是 1,V3 的值是 2。Oracle 数据库的默认隔离级别其实就是“读提交”MySQL默认的隔离级别是可重复读(Repeatable Read)因此对于一些从 Oracle 迁移到 MySQL 的应用,为保证数据库隔离级别的一致,你一定要记得将 MySQL 的隔离级别设置为“读提交”。配置的方式是,将启动参数 transaction-isolation 的值设置成 READ-COMMITTED。事务隔离的实现在 MySQL 中,实际上每条记录在更新的时候都会同时记录一条回滚操作。记录上的最新值,通过回滚操作,都可以得到前一个状态的值。假设一个值从 1 被按顺序改成了 2、3、4,在回滚日志里面就会有类似下面的记录长事务长事务意味着系统里面会存在很老的事务视图。由于这些事务随时可能访问数据库里面的任何数据,所以这个事务提交之前,数据库里面它可能用到的回滚记录都必须保留,这就会导致大量占用存储空间。set autocommit=0,这个命令会将这个线程的自动提交关掉。意味着如果你只执行一个 select 语句,这个事务就启动了,而且并不会自动提交。set autocommit=1;表示MySQL自动开启和提交事务。 比如执行一个update语句,语句只完成后就自动提交了。不需要显示的使用begin、commit来开启和提交事务。 所以,当我们需要对某些操作使用事务的时候,手动的用begin、commit来开启和提交事务。【查找长事务】可以在 information_schema 库的 innodb_trx 这个表中查询长事务,比如下面这个语句,用于查找持续时间超过 60s 的事务。select * from information_schema.innodb_trx where TIME_TO_SEC(timediff(now(),trx_started))>60【避免长事务】监控 information_schema.Innodb_trx 表,设置长事务阈值,超过就报警 / 或者 kill;如果使用的是 MySQL 5.6 或者更新版本,把 innodb_undo_tablespaces 设置成 2(或更大的值)。如果真的出现大事务导致回滚段过大,这样设置后清理起来更方便。确认是否使用了 set autocommit=0 如果是0把它改成 1确认是否有不必要的只读事务。通过 SET MAX_EXECUTION_TIME 命令,来控制每个语句执行的最长时间,避免单个语句意外执行太长时间。
-
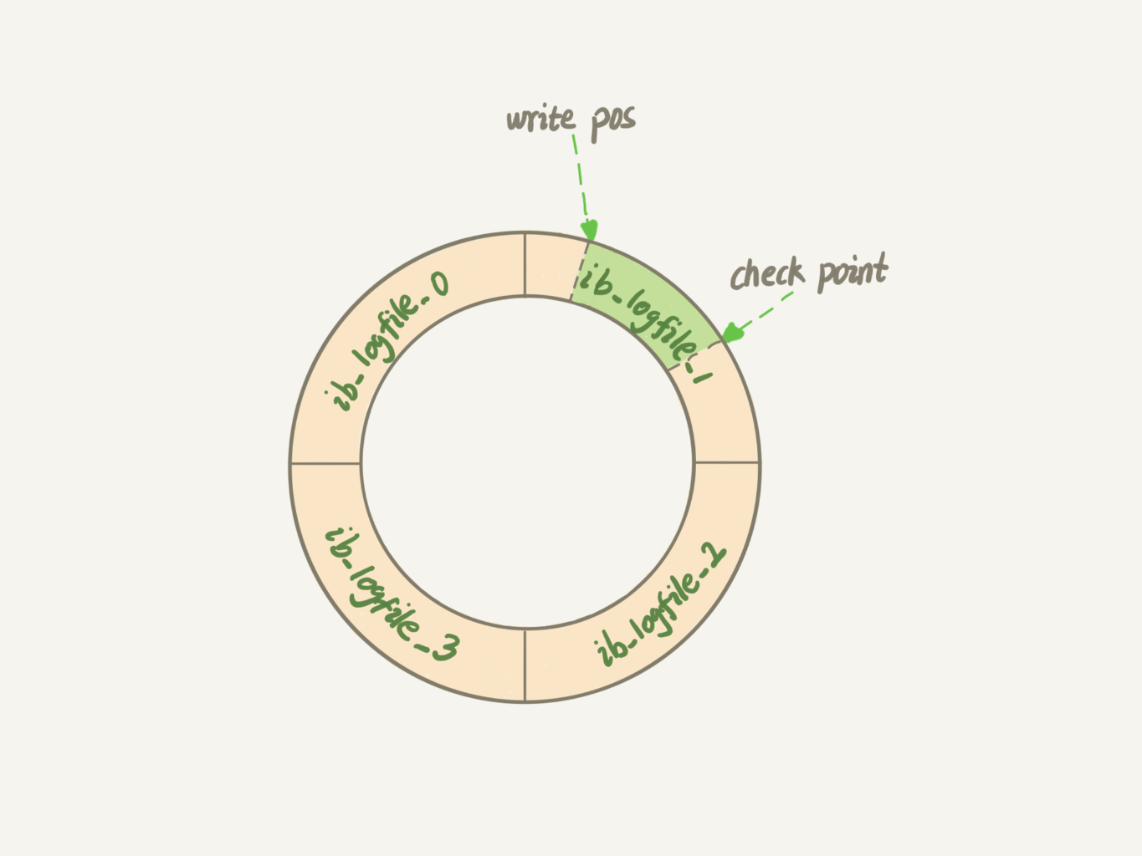
笔记 | 一条SQL更新语句是如何执行的? 重要的日志模块:redo log(重做日志)WAL(Write-Ahead Logging) 技术: 先写日志,再写磁盘当有一条记录需要更新的时候,InnoDB 引擎就会先把记录写到 redo log里面,并更新内存,这个时候更新就算完成了。同时,InnoDB 引擎会在适当的时候,将这个操作记录更新到磁盘里面redo log 是循环写的,空间固定会用完;binlog 是可以追加写入的。“追加写”是指 binlog 文件写到一定大小后会切换到下一个,并不会覆盖以前的日志。write pos: 当前记录的位置,一边写一边后移,写到第 3 号文件末尾后就回到 0 号文件开头checkpoint:是当前要擦除的位置,也是往后推移并且循环的,擦除记录前要把记录更新到数据文件。write pos 和 checkpoint 之间:是“粉板”上还空着的部分,可以用来记录新的操作write pos 追上 checkpoint:表示“粉板”满了,这时候不能再执行新的更新,得停下来先擦掉一些记录,把 checkpoint 推进一下【crash-safe】redo log 是 InnoDB引擎所特有的,所以我们如果再使用InnoDB引擎创建表时,如果数据库发生异常重启,之前提交的记录都不会丢失。 InnoDB正因为有了 redo log(重做日志),才有了 crash-safe 的能力(即使mysql服务宕机,也不会丢失数据的能力)。redo log 是 InnoDB 引擎特有的日志重要的日志模块:binlog(归档日志)【更新流程】mysql> update T set c=c+1 where ID=2;执行器先找引擎取 ID=2 这一行。ID 是主键,引擎直接用树搜索找到这一行。如果 ID=2 这一行所在的数据页本来就在内存中,就直接返回给执行器;否则,需要先从磁盘读入内存,然后再返回。执行器拿到引擎给的行数据,把这个值加上 1,比如原来是 N,现在就是 N+1,得到新的一行数据,再调用引擎接口写入这行新数据。引擎将这行新数据更新到内存中,同时将这个更新操作记录到 redo log 里面,此时 redo log 处于 prepare 状态。然后告知执行器执行完成了,随时可以提交事务。执行器生成这个操作的 binlog,并把 binlog 写入磁盘。执行器调用引擎的提交事务接口,引擎把刚刚写入的 redo log 改成提交(commit)状态,更新完成。redo log 用于保证 crash-safe 能力。innodb_flush_log_at_trx_commit 这个参数设置成 1 的时候,表示每次事务的 redo log 都直接持久化到磁盘bingo是server层特有的日志Binlog有两种模式,statement 格式的话是记sql语句, row格式会记录行的内容,记两条,更新前和更新后都有。redolog和binlog的区别redo log 是 InnoDB 引擎特有的;binlog 是 MySQL 的 Server 层实现的,所有引擎都可以使用。redo log 是物理日志,记录的是“在某个数据页上做了什么修改”;binlog 是逻辑日志,记录的是这个语句的原始逻辑,比如“给 ID=2 这一行的 c 字段加 1 ”。redo log 是循环写的,空间固定会用完;binlog 是可以追加写入的。“追加写”是指 binlog 文件写到一定大小后会切换到下一个,并不会覆盖以前的日志。【例子】一个完整的交易过程:账本记上 卖一瓶可乐(redo log为 prepare状态),然后收钱放入钱箱(bin log记录)然后回过头在账本上打个勾(redo log置为commit)表示一笔交易结束。如果收钱时交易被打断,回过头来整理此次交易,发现只有记账没有收钱,则交易失败,删掉账本上的记录(回滚);如果收了钱后被终止,然后回过头发现账本有记录(prepare)而且钱箱有本次收入(bin log),则继续完善账本(commit),本次交易有效。
-
关于-安和桥 关于安和桥北《安和桥》是民谣歌手 宋冬野所演唱的一首原创歌曲很多人不知道安和桥这个地方它坐落于北京海淀区中部,是清雍正二年(1724年)为方便人们出行建设的一个桥,取“安澜平和”之意称“安和桥”。平时听这首歌 总是会让人联想到爱情但其实是宋冬野写给去世奶奶的宋冬野从小父母离异 跟着奶奶一起长大年少时奶奶总喜欢抱着他 去离家不远的安和桥那里散步专辑《安河桥北》中封面的照片就是奶奶抱着宋冬野 在安河桥哪里拍的宋冬野上初中的时候喜欢班上的一个女同学而女同学喜欢弹吉他的男生于是宋冬野用了奶奶的养老保险花了148块钱 买了他人生当中的第一把吉他最后女孩没追到 吉他却放不下了而奶奶也在宋冬野 还没有出名的时候就去世了宋冬野写下安和桥 抒发对奶奶的思念之情民谣有三 姑娘、吉他、南北方听者有三 香烟、孤独、还有酒姑娘是爱情 吉他是理想 南北是远方 香烟是回忆故事很长还记得之前一个朋友给我说过大冰的小屋的故事当时 也还不知道什么意思后来渐渐发现 一些东西错过了 就是一辈子遗憾现在 对于我的观念来说 活得开心就好 何必在意那么多他们都说 唱民谣的都是有故事的人喜欢民谣的也是有故事的人也有人说 民谣是现代都市人内心向往的一片净土也许 喜欢民谣的内心都是孤独的人呐喜欢一个人静静坐在 听着安和桥一个人独来独往 内心炙热滚烫 外表冷酷热爱着世界 热爱着远方的那个她
-
笔记 | 一条SQL查询语句是如何执行的? Mysql主体分两部分首先,MySQL可以分为Server 层和存储引擎层两部分。Server 层Server 层包括连接器、查询缓存、分析器、优化器、执行器等,涵盖 MySQL 的大多数核心服务功能,以及所有的内置函数(如日期、时间、数学和加密函数等),所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图等存储引擎 层而存储引擎层负责数据的存储和提取。其架构模式是插件式的,支持 InnoDB、MyISAM、Memory 等多个存储引擎。现在最常用的存储引擎是 InnoDB,它从 MySQL 5.5.5 版本开始成为了默认存储引擎连接器第一步,你会先连接到这个数据库上,这时候接待你的就是连接器。连接器负责跟客户端建立连接、获取权限、维持和管理连接mysql -h$ip -P$port -u$user -p如果用户名或密码不对,你就会收到一个"Access denied for user"的错误,然后客户端程序结束执行如果用户名密码认证通过,连接器会到权限表里面查出你拥有的权限。之后,这个连接里面的权限判断逻辑,都将依赖于此时读到的权限 如果要重载权限就要重新链接链接闲置·sleep连接完成后,如果你没有后续的动作,这个连接就处于空闲状态,你可以在 show processlist 命令中看到它客户端如果太长时间没动静,连接器就会自动将它断开。这个时间是由参数 wait_timeout 控制的,默认值是 8 小时查询缓存之前执行过的语句及其结果可能会以 key-value 对的形式,被直接缓存在内存中key 是查询的语句,value 是查询的结果所以,MySQL 拿到一个查询请求后,会先到查询缓存看看,之前是不是执行过这条语句如果缓存中能直接查到这个key的话,就会把对应这个key的value直接返回给客户端但是大多数情况下建议不要使用查询缓存查询缓存的失效非常频繁,只要有对一个表的更新,这个表上所有的查询缓存都会被清空所以,MySQL有这样的一个配置,你可以将参数 query_cache_type 设置成 DEMAND,这样对于默认的 SQL 语句都不使用查询缓存。而对于你确定要使用查询缓存的语句,可以用 SQL_CACHE 显式指定 mysql> select SQL_CACHE * from T where ID=10;注意:MySQL 8.0 版本直接将查询缓存的整块功能删掉了,也就是说 8.0 开始彻底没有这个功能了分析器分析器,是在没有命中缓存的情况下 开始分析sql语句1.分析器先会做“词法分析”MySQL 从你输入的"select"这个关键字识别出来,这是一个查询语句。它也要把字符串“T”识别成“表名 T”,把字符串“ID”识别成“列 ID”2.第二就要做“语法分析”判断你输入的这个 SQL 语句是否满足 MySQL 语法一般语法错误会提示第一个出现错误的位置,所以你要关注的是紧接“use near”的内容。优化器优化器是在表里面有多个索引的时候,决定使用哪个索引;或者在一个语句有多表关联(join)的时候,决定各个表的连接顺序。同一条sql可以不同的拼接组合查询 但是每一种执行的效率时间都会有所不同 而优化器就是选择最优的组合去查询执行器要先判断一下你对这个表 T 有没有执行查询的权限,如果没有,就会返回没有权限的错误,如下所示 (在工程实现上,如果命中查询缓存,会在查询缓存返回结果的时候,做权限验证。查询也会在优化器之前调用 precheck 验证权限)mysql> select * from T where ID=10; ERROR 1142 (42000): SELECT command denied to user 'b'@'localhost' for table 'T'如果有权限,就打开表继续执行。打开表的时候,执行器就会根据表的引擎定义,去使用这个引擎提供的接口在没有索引的情况下:1.调用 InnoDB 引擎接口取这个表的第一行,判断 ID 值是不是 10,如果不是则跳过,如果是则将这行存在结果集中;2.调用引擎接口取“下一行”,重复相同的判断逻辑,直到取到这个表的最后一行。3.执行器将上述遍历过程中所有满足条件的行组成的记录集作为结果集返回给客户端。在有索引的情况下:第一次调用的是“取满足条件的第一行”这个接口之后循环取“满足条件的下一行”这个接口这些接口都是引擎中已经定义好的。你会在数据库的慢查询日志中看到一个 rows_examined的字段,表示这个语句执行过程中扫描了多少行。这个值就是在执行器> 每次调用引擎获取数据行的时候累加的。在有些场景下,执行器调用一次,在引擎内部则扫描了多行,因此引擎扫描行数跟 rows_examined 并不是完全相同的。